The well-accepted and popular method of interacting with electronic devices such as televisions, computers, phones, and tablets is speech. It is a dynamic process, and human speech is exceptionally complex. The speech recognition engines offer better accuracy in understanding the speech due to technological advancement. A study indicates that from 2019 to 2025, the global speech and voice recognition market can reach $26.79 billion.
Developers integrate speech recognition into the applications as they are useful in understanding what is said. In smart watches, household appliances and in-car assistants’ speech recognition are used. The Speech Recognition Software has to deal with a variety of speech patterns and individuals’ accents.
Here in this article, you will come to know about the working, benefits and best free and open source speech recognition software solutions available in the market.
What is Speech Recognition?
The technology-speech recognition permits spoken input into systems. It is considered an ability of a machine to recognize words and phrases in spoken language and then change it to the machine-readable format. In simple words, it means that it is a computer program that is taught to take the input of human speech which is then interpreted and then finally written out into the text.
Benefits of using Open Source Speech Recognition Software
- Assist companies to save time and money by mechanizing business processes. On phone calls, it provides instant sights on what’s happening.
- More cost-effective as the software performs the task of speech recognition and transcription faster and more accurately than a human.
- The cost of speech recognition and transcription software is less per minute and is measured more accurately than a human performing at the same rate.
- Easy to use and readily available. In computers and mobile devices, speech recognition software is frequently installed in computers and mobile devices that allow for easy access.
Best 7 Free and Open Source Speech Recognition Software Solutions:
1 Simon
Simon is considered very flexible speech recognition software meant for the free and open source. It allows customization for any applications wherever speech recognition is required. It can work with any dialect and is not bound to any language. It can replace the mouse and keyboard.
Simon makes use of KDE libraries, CMU SPHINX or Julius together with the HTK and it runs on Windows and Linux. One can open the URLs and programs, type configurable text snippets, control the mouse and keywords and simulate shortcuts.
It turns audio into text and allows voice commands. You can check out Simon if you would like to talk to your computer.
(Source : Simon)
Features:
- From the input, it can execute all sorts of commands. It receives information from the server Simond.
- Command-and-control solutions are appropriate for disabled people.
- The same version of Simon can be used with all languages and dialects because of its architecture. If required then you can even mix languages within one model.
- An exclusive do-it-yourself approach is provided to speech recognition by Simon. To create language and acoustic models from scratch, it provides an easy to use end-user interface.
- From other users, the end-user can easily download established use cases and can share his or her cases.
- It controls many different types of software including web browsers, media centers, email clients by making use of few words like “left,” “right,” “ok,” “stop” etc.
2 Kaldi
Kaldi is an open source speech recognition software that is freely available under the Apache License. In John Hopkins University, the development fired up at a workshop in 2009 that called “Low Development Cost, High-Quality Speech Recognition for New Languages and Domains.”
On May 14, 2011, the code for Kaldi was released after working on the project for a few years. Quickly Kaldi gained a reputation for its ease to work with. It is written in C++ and is intended to be used mainly for acoustic modeling research.

(Source: Kaldi)
Features:
- Supports full covariance structures along with Gaussian mixture modules along with diagonal.
- Holds MMI and boosted MMU.
- Code-level integration with Finite State Transducers accumulates against the OpenFst toolkit.
- Possesses tools for changing LMs in the standard ARPA format to FSTs.
- Enjoys the support of the general linear algebra along with a matrix library that wraps standard Basic Linear Algebra Subroutines and Linear Algebra Package routines.
- An extensible design that features-space discriminative training.
- Offers complete recipes and deep neural networks.
- Use maximum likelihood linear regression (MLLR) to support model-space adaptation and use feature-space MLLR to support feature-space adaptation.
3 CMUSphinx
The short form of CMUSphinx is Sphinx. It is a speaker-independent large vocabulary continuous speech recognizer that is released under the BSD style license. This is a group of speech recognition systems which is developed by the Carnegie Mellon University.
The number of packages is found in this open source and free speech recognition software. Each is designed for different types of tasks and applications.
- Pocketsphinx - A lightweight speech recognition engine which is written in C. It is specially designed for handheld and mobile devices.
- Sphinx base - Holds the necessary libraries which are shared by the CMU Sphinx trainer, Sphinx decoders, some common utilities that influence acoustic features and audio files.
- Sphinx4 - Speaker independent, a state-of-the-art, continuous speech recognition system that is written in the Java programming language.
- Sphinxtrain - Open source acoustic model trainer of Carnegie Mellon University.

(Source : CMUSphinx)
Toolkit Features:
- For low-resource platforms, the CMUSphinx tools are designed. Efficient speech recognition is possible because of the state of the art speech recognition algorithms.
- Holds a flexible design that centers on realistic application development and not on research.
- Ample of tools meant for the speech recognition related purposes like keyword spotting, pronunciation evaluation, and alignment.
- Encourage various languages like Mandarin, Dutch, German, Russian, English, and French. Enjoys the ability to build models for other languages.
4 Mozilla
An open source voice recognition tool is released by the Mozilla that it states is “close to the human level performance.” It is free speech recognition software for developers to plug into their projects. Mozilla Senior Vice President of Emerging Technologies Sean White wrote in a blog post that “We at Mozilla believe technology should be open and accessible to all, and that includes voice.”

(Source: Mozilla)
Features:
- Project Common Voice by Mozilla is a campaign that asks people to donate recordings of their voices to an open repository.
- Speech algorithms enable developers to create speech interfaces that use considerably simplified software architectures.
- Mozilla DeepSpeech is an open source Tensorflow-based speech-to-text processor that has reasonably high accuracy.
- DeepSpeech, the speech recognition tool has a remarkable per-word error rate of near about 6.5%.
- Uses open source code algorithms and TensorFlow machine learning toolkit to build its STT engine.
- Better awareness of privacy concerns and is considered more powerful hardware.
- The DeepSpeech project is also available in many languages such as Python (3.6); which allows having its working in seconds.
5 Julius
Julius is measured as the free high-performance and two-pass large vocabulary continuous speech recognition decoder software (LVCSR) for speech-related developers and researchers. It carries out multi-model decoding, a recognition utilizing some LMs and AMs concurrently with a single processor. At run time it supports the “hot plugging” of arbitrary modules.
To deal with other toolkits like HTK, CMU-Cam SLM, this open source speech recognition software adopts standard formats. Various types of speech recognition system can be built by putting up their own models and modules that are apt for the task. Both acoustic models and language models are pluggable. The various applications offer the speech recognition capability as the core engine is put into practice as an embeddable library. The user can extend the engine as the recent version supports plug-in capability.
(Source: Julius)
Features:
- For work area less than 32Mbytes memory is required.
- Precise, hi-speed and real-time recognition based on 2-pass strategy.
- Supports LM of grammar, isolated words and N-gram.
- In ARPA standard format any LM and in HTK ascii hmmdefs format AM is used.
- Can set various search parameters due to high configurability.
- In English/Japanese there is full source code documentation and manual.
- For microphone and network, input works as the on-the-fly recognition.
- Short pauses delimit input. Enjoys successive decoding.
- Input rejection is GMM based. Word-graph and N-best output. Confusion network output.
- On word, phoneme and state level there is forced alignment.
- Confidence scoring, control API and server mode.
- For tuning the performance has many search parameters.
- For a result, output holds character code conversion.
- Long N-gram support and run with forward/backward N-gram only.
- In a single thread enjoys the arbitrary multi-model decoding.
- Word acknowledgment is speedy isolated.
- LM function is user-defined.
6 Dictation Bridge
Dictation Bridge is a free and open source dictation solution for NVDA and Jaws. It is a gateway between NVDA, Jaws screen readers, either Dragon Naturally Speaking or Windows Speech Recognition. Both Windows Speech Recognition and Dragon can be controlled by Jaws users.
In Dragon and Windows Speech Recognition (WSR) it can echoes back the dictated text. It serves as an extensive collection of verbal commands that can control screen readers and perform a variety of other tasks with Dragon products.

(Source:Dictation Bridge)
Features:
- Speech only supports of the WSR correction box and help to control NVDA from Dragon and WSR. Only Dragon commands have been written at this time.
- From Dragon, it possesses the command NVDA by voice.
- While using Dragon, a verbal notification of the microphone status comes. No support needs to be created as WSR has this built-in feature.
- Provides all the features for both NVDA and JAWS in a fully featured dictation plug-in or set of configurations.
- First ever dictation solution for screen readers that takes in a wide-ranging collection of verbal commands which users use to control the screen reader.
- Can be translated into any of the 35 languages that are supported by Windows Speech Recognition and more than 43 languages hold up by NVDA.
- This free and libre open source software (FLOSS) holds the highest quality documentation.
- Affords the community the freedom to modify, learn from, add to, repurpose or do anything else.
- Capable of handing off the functionality between screen readers if both NVDA and Jaws versions are installed.
7 Mycroft
Mycroft is the name of a set of software and hardware tools that make use of natural language processing and machine learning which offers an open source voice assistant. It is the private and open voice solution for consumers and enterprise. This open source voice assistant can be extended and expanded to the limits of the imagination.
It runs anywhere - on a desktop computer, inside an automobile or on a Raspberry Pi. It can be freely remixed, extended and improved. It may be used in anything from a science project to an enterprise software application.

(Source: Mycroft)
Features:
- The code used by Mycroft can be examined, customized, copied and contributed back to the Mycroft community for everyone to enjoy.
- It uses opt-in privacy that means it will only record what is said to Mycroft with explicit permission.
- Runs on a wide range of software platforms and hardware. You can run Mycroft on the devices as per the choice.
- Works as an active, engaged and helpful community.
- Holds messaging and reminder function.
- Enjoys audio record, speech recognition, speech-to-text, text-to-speech, machine learning, software library, natural language processing, and Linux OS.
Apart from the in-depth description of the best free and open-source speech recognition software, you can also try Braina Pro, Sonix, Winscribe Speech Recognition, Speechmatics. Dragon NaturallySpeaking is one more popular speech recognition software which you can explore here.
Dragon NaturallySpeaking
By merely speaking, you can improve the documentation productivity with Dragon NaturallySpeaking tool. You have to talk, and your words will appear on the screen. Your computer will obey your commands. Whether your business is of financial services, education, or healthcare; Dragon NaturallySpeaking software will provide you appropriate solutions to your business needs.
This software is 99% accurate and is three times faster than typing. This software allows individuals to create and share high-quality documentation and helps in simplifying the complex workflows. You can become more productive by using this software.
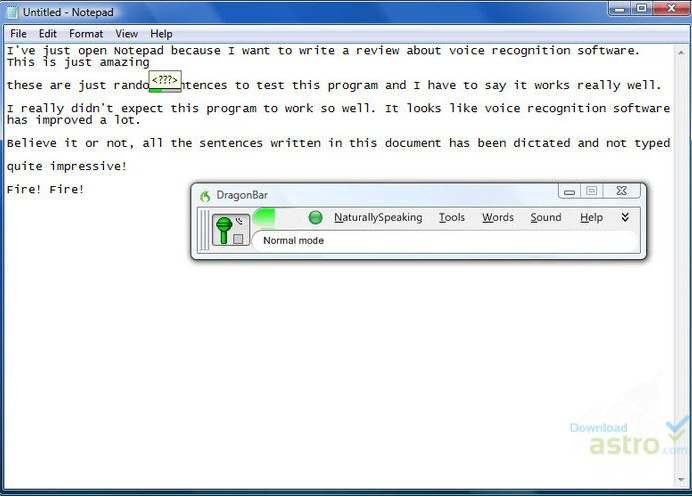
(Source: Dragon NaturallySpeaking)
Features:
- Assists in several daily activities like sending emails, web surfing, dictating homework assignments.
- Working individuals and small businesses can create and transcribe documents through dragon professional.
- Synchronization is possible with Dragon Anywhere.
- It streamlines the legal documentation with dragon legal individual.
- With speed and accuracy, it controls the computer by voice.
Conclusive thought
In this article, you will get comprehensive information regarding open source speech recognition solutions. From the list, you can choose one of the most promising free open source speech recognition software that can efficiently meet your demands and requirements.
The open and free source speech recognition software can construct the speech recognition application that requires advanced speech processing techniques. All these techniques are realized by specialized speech processing software.
Depending on the open source speech recognition software you can make use of speech recognition to speak to your computer, read out documents, open, edit and send emails. The free speech recognition software is available in many forms like web, mobile, and desktop. Make sure that whatever speech recognition software you choose, it should be precise in identifying the words you speak and allow you to place in formatting options like symbols and special characters.
If you are looking for more options on the best speech recognition software to construct your speech recognition application, then indeed this article will provide you immense and in-depth knowledge and understanding on the same.
In case before now you have tried out any of the above listed speech recognition software, then feel free to share your precious views and feedback on the same.





